通义点金这个平台有没有现成的信贷审批模版?能不能用它改造成自己想要的版本
平台上会有一些预置的标准化模板,客户可以直接使用;如果金融机构有自己个性化的模板需求,平台支持板结构的定制、内容风格的定制,确保每家金融机构都会得到符合自己要求的交付物。
实际信贷报告AI表现如何?出一份报告需要多久?准确率高不高?需要人工检查吗?
AI出一份报告在10-15分钟左右;至于准确率,如果数据基础不错的话,整体准确率一般能做到90%以上;需要人工检查,针对关键点做二次检查就行;整体上,自动生成+二次检查的时间,效率上还是有很大的提升。
生成报告如果出错了算谁的?能不能看到它是根据哪些材料做判断的?
首先从目前来看,大模型仍处于辅助阶段,每份报告均需要人工确认后方能生效;在系统层面,大模型生成的内容支持溯源,无论是来源于RAG文件,还是搜索引擎,还是API接口,都支持溯源。
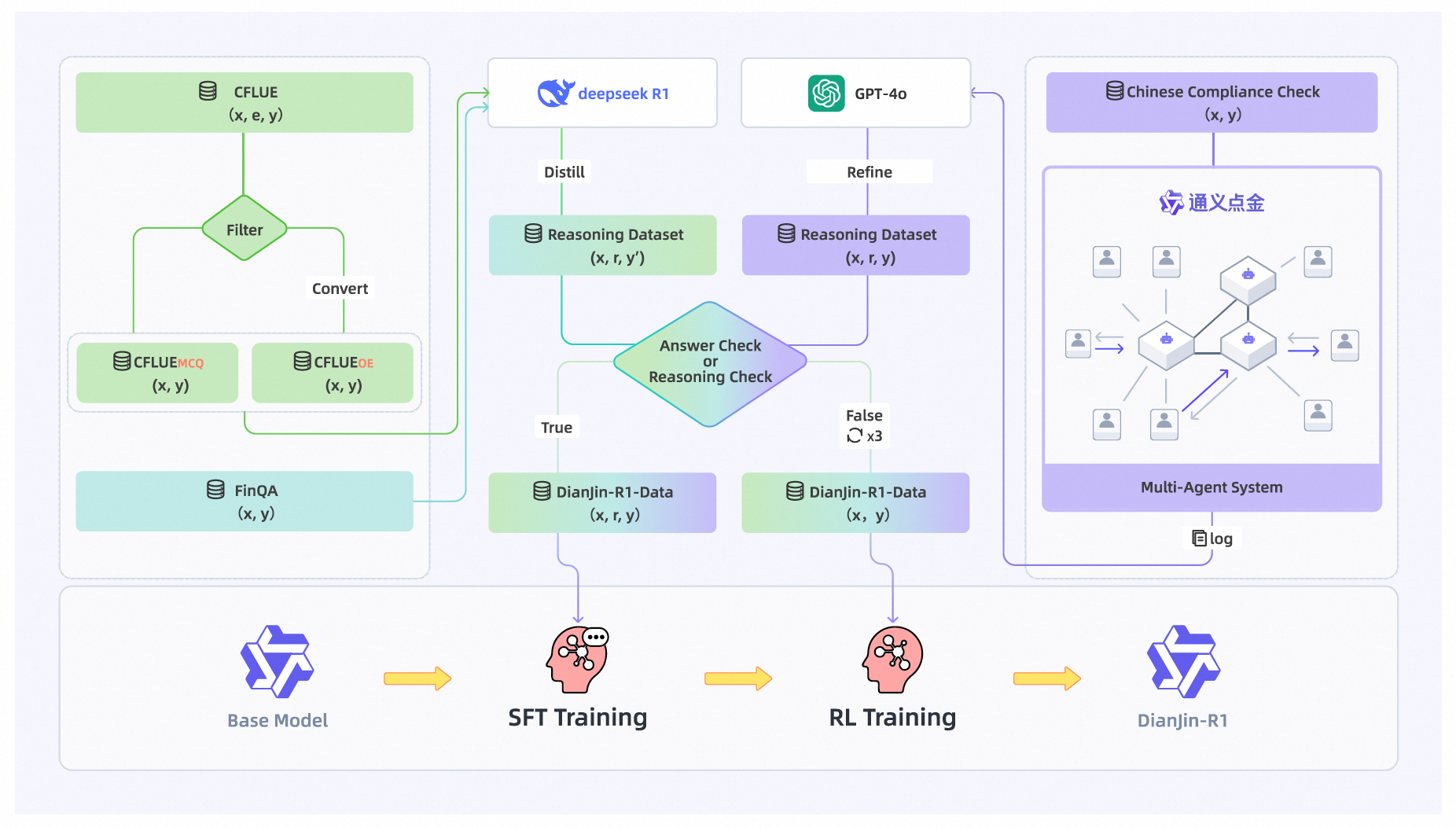
SFT训练专家模型很有意思,请问训练预料包含行业评价标准类数据吗,怎么防止小模型学歪了
为防止小模型“学歪”,一般我们采取以下措施:一是数据层面,通过清洗、平衡数据分布并引入对抗样本提升泛化能力;二是算法层面,采用正则化、知识蒸馏等技术约束模型学习,避免过拟合;三是,仍然建议,大模型输出的结果,给到业务专家二次审核确认,保证安全合规。
不同银行的流水格式不一样,AI如何统一处理?如果企业的营收和税务数据不一样,怎么处理
不同银行的流水格式不一致,主要体现在版面格式和字段名描述上。处理过程中会结合大语言模型、多模态大模型,综合使用优化效果;对于数据点不一致的问题,可以在大模型提示词里做要求,列出来具体的不一致的点,给到人工做校验和处理。
我们在公司里,已经做过不同领域任务的OCR模型了,Qwen-VL可以替代他们吗?
两者是结合互补关系,而不是替代关系。在标准固定的内容识别场景,推荐OCR使用,速度快,准确率高;在非文字类的图像领域,进行图片理解和推理场景可以直接使用VL;在非固定的票据/表单识别场景,也适合VL模型;还有种组合文字类图像可以OCR+VL结合使用,比如:内容审核场景,可以将原始图片、OCR识别的结果一起发送给VL进行内容审核和纠正,提升准确性。
对Qwen-VL模型做训练,训练数据的格式和量级有什么要求?一般基于多大尺寸的来做?
VL的训练语料格式,格式上包含图像和对应的文字描述;量级上,取决于任务的复杂度和训练方法,一般在1k级别以上。对于模型尺寸,VL有7b、32b、72b三种尺寸,常见的使用7b较多,因为VL模型微调不仅为了提升模型效果,还有一个诉求是降低算力需求,提升推理性能
AI 助手(Qwen-VL)实际能有多少效率的提升?能给人工减少多少工作量?
VL对工作效率的提升,主要体现在两种场景上。第一种是原有OCR小模型完全做不了的,例如:图像内容理解和推理、视频内容审核,这种,这种效率提升很大,人工可能1小时,VL 1分钟就可能完成。第二种是原来OCR已经挺准确了,加上VL只是针对一些疑难杂症做些修补,这种对效率的提升相对就会小一些。总的来说,能给人工减少多少工作量,取决于具体应用场景和VL能达到的准确度。
金融数据都很敏感的,模型来验证会安全吗,还有数据隐私那些可以保证吗?
大部分金融客户都是本地化部署Qwen-VL模型,对图片进行文字提取或图片理解,所以不会出现数据敏感泄露问题。有些客户通过互联网访问阿里云Qwen-VL模型服务,阿里云针对用户数据隐私保护,特别是针对用户的Prompt安全,使用加密算法进行安全控制保护,推理完成后对明文进行销毁。
通义点金这个平台有没有现成的信贷审批模版?能不能用它改造成自己想要的版本
平台上会有一些预置的标准化模板,客户可以直接使用;如果金融机构有自己个性化的模板需求,平台支持板结构的定制、内容风格的定制,确保每家金融机构都会得到符合自己要求的交付物。
实际信贷报告AI表现如何?出一份报告需要多久?准确率高不高?需要人工检查吗?
AI出一份报告在10-15分钟左右;至于准确率,如果数据基础不错的话,整体准确率一般能做到90%以上;需要人工检查,针对关键点做二次检查就行;整体上,自动生成+二次检查的时间,效率上还是有很大的提升。
生成报告如果出错了算谁的?能不能看到它是根据哪些材料做判断的?
首先从目前来看,大模型仍处于辅助阶段,每份报告均需要人工确认后方能生效;在系统层面,大模型生成的内容支持溯源,无论是来源于RAG文件,还是搜索引擎,还是API接口,都支持溯源。
SFT训练专家模型很有意思,请问训练预料包含行业评价标准类数据吗,怎么防止小模型学歪了
为防止小模型“学歪”,一般我们采取以下措施:一是数据层面,通过清洗、平衡数据分布并引入对抗样本提升泛化能力;二是算法层面,采用正则化、知识蒸馏等技术约束模型学习,避免过拟合;三是,仍然建议,大模型输出的结果,给到业务专家二次审核确认,保证安全合规。
不同银行的流水格式不一样,AI如何统一处理?如果企业的营收和税务数据不一样,怎么处理
不同银行的流水格式不一致,主要体现在版面格式和字段名描述上。处理过程中会结合大语言模型、多模态大模型,综合使用优化效果;对于数据点不一致的问题,可以在大模型提示词里做要求,列出来具体的不一致的点,给到人工做校验和处理。
我们在公司里,已经做过不同领域任务的OCR模型了,Qwen-VL可以替代他们吗?
两者是结合互补关系,而不是替代关系。在标准固定的内容识别场景,推荐OCR使用,速度快,准确率高;在非文字类的图像领域,进行图片理解和推理场景可以直接使用VL;在非固定的票据/表单识别场景,也适合VL模型;还有种组合文字类图像可以OCR+VL结合使用,比如:内容审核场景,可以将原始图片、OCR识别的结果一起发送给VL进行内容审核和纠正,提升准确性。
对Qwen-VL模型做训练,训练数据的格式和量级有什么要求?一般基于多大尺寸的来做?
VL的训练语料格式,格式上包含图像和对应的文字描述;量级上,取决于任务的复杂度和训练方法,一般在1k级别以上。对于模型尺寸,VL有7b、32b、72b三种尺寸,常见的使用7b较多,因为VL模型微调不仅为了提升模型效果,还有一个诉求是降低算力需求,提升推理性能
大模型驱动的金融助手,向金融业务开发者提供更便捷的人工智能应用开发平台。